
Laut einer aktuellen McKinsey-Analyse könnten bis 2030 rund 7 Billionen US-Dollar in den Aufbau von Compute-Infrastruktur fließen – vom Stromanschluss bis zum GPU-Server.
Allein für KI-Workloads sei ein Investitionsbedarf von 5,2 Billionen USD zu erwarten, verteilt auf Chips, Rechenzentren, Stromversorgung und Kühlung.
AI workloads are reshaping the cost of compute—doubling power needs and driving data center demand to unprecedented levels.
Die Frage lautet also nicht mehr ob Rechenleistung zur Engpassressource wird – sondern wann und für wen.
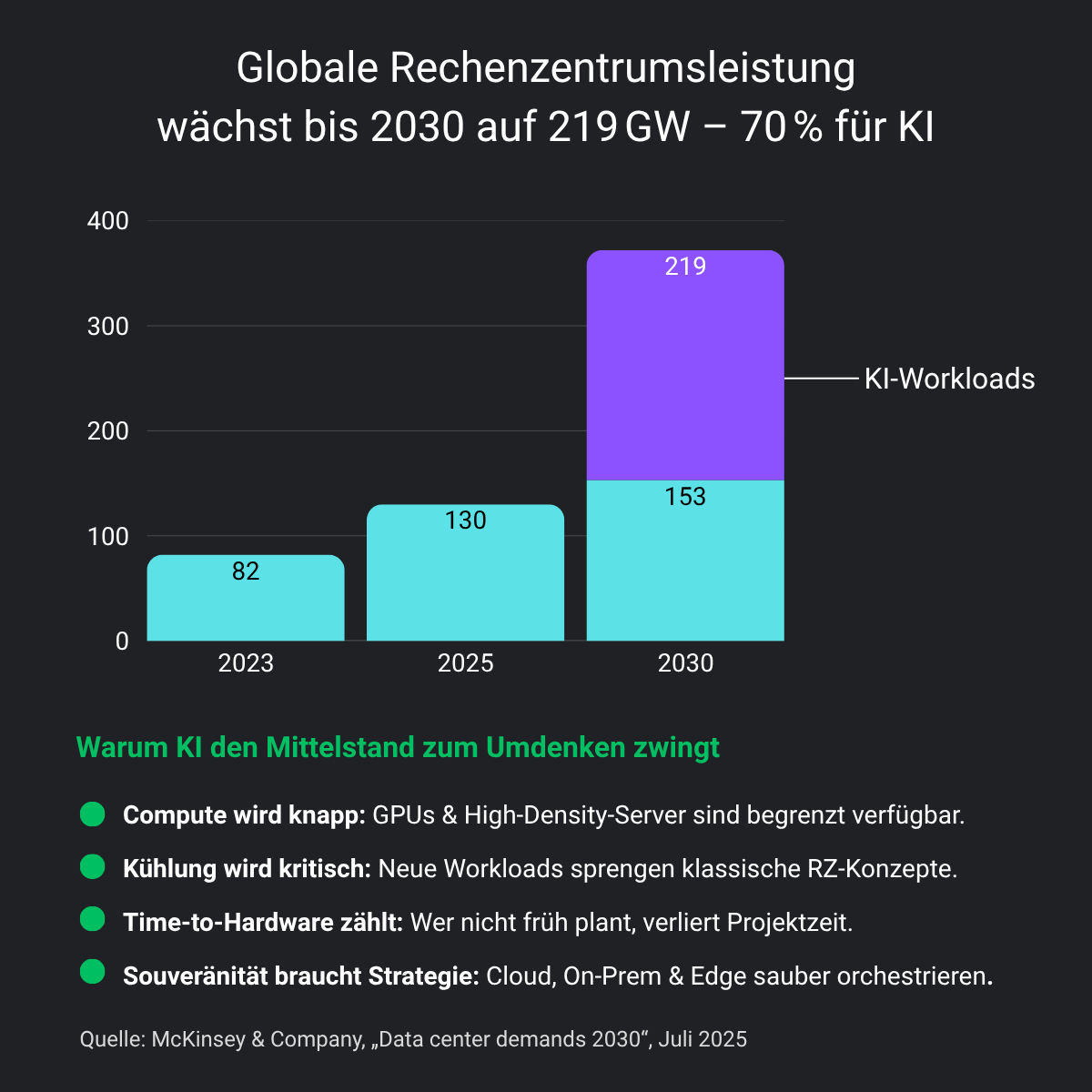
Zwischen Milliardenprognose und technischer Realität liegt eine Lücke
McKinsey benennt eine zentrale Herausforderung: die Unsicherheit der Compute-Nachfrage.
Zwar geht das „Accelerated Case“-Szenario von einem 30-fachen Anstieg der AI-Workload bis 2030 aus. Doch die Bandbreite der Vorhersagen ist enorm – und Fehler kosten Milliarden.
Der Unterschied zwischen Unterbau und Überbau wird zur wirtschaftlichen Kernfrage.
Für uns als Distributor ist das keine abstrakte Makro-Prognose.
Wenn ein Kunde dringend High-End-GPUs benötigt, die weltweit gerade keiner liefern kann – oder Monate im Voraus eine Infrastruktur beschafft, die dann nie produktiv geht – dann wird „Unsicherheit der Nachfrage“ zur realen Herausforderung im Projektgeschäft.
Und viele Systemhäuser kennen genau dieses Spannungsfeld nur zu gut.
Gleichzeitig macht die Studie deutlich:
70–80 % der AI-bedingten Infrastrukturkosten fallen außerhalb der Chip-Ebene an.
Es geht um Energie, Fläche, Kühlung – und verlässliche Hardware.
Compute ist nicht beliebig skalierbar – und schon gar nicht virtuell
Auch wenn Public Clouds nach außen „unendlich skalierbar“ erscheinen, bleibt die physikalische Realität eine andere:
Compute ist Hardware. Sie muss produziert, betrieben, gekühlt und vorgehalten werden.
Das gilt im Hyperscaler-Modell ebenso wie in Forschung, Industrie und Mittelstand. McKinsey spricht zu Recht von einer „physical bottleneck to AI progress“ – verursacht durch Energieengpässe, Flächenknappheit, Infrastrukturverzögerungen und die Verfügbarkeit spezialisierter Komponenten.
Wer hier zu spät plant oder auf falsche Skalierungsmodelle setzt, verliert.
Was folgt daraus für IT-Entscheider in Europa?
Viele Unternehmen spüren den Druck bereits – besonders in regulierten oder performancekritischen Bereichen wie Medizin, Industrieautomatisierung, Forschung oder Automotive.
- Cloud-only reicht nicht, wenn Energiebedarf, Datenschutz oder Latenz zum Engpass werden.
- Edge-Deployments sind oft kein „Add-on“, sondern Voraussetzung für Echtzeitfähigkeit und Souveränität.
- Hybride Strategien müssen geplant, nicht gehofft werden.
Ein konkretes Beispiel:
Für ein international tätiges Unternehmen aus der molekularbiologischen Wirkstoffforschung haben wir 2024 eine GPU-beschleunigte HPC-Plattform umgesetzt – mit skalierbarer Architektur, NVIDIA H100 SXM GPUs, über 900 GB/s Bandbreite und mehr als 512 GB RAM pro System. Ziel war die Beschleunigung KI-gestützter Prozesse wie Virtual Screening und Proteinstruktur-Analysen – Verfahren, bei denen Rechenzeit nicht nur Geld kostet, sondern Forschungszeit.
Die Herausforderung lag nicht in der Software, sondern – wie so oft – in der Infrastruktur. Es ging um:
- eine zuverlässige Versorgung der Systeme mit Strom und Kühlung,
- die Auswahl sinnvoller Komponenten für Simulationslasten,
- und die Frage, wie sich zukünftige Anforderungen skalierbar abbilden lassen, ohne überzubauen.
➡ Genau das meint McKinsey, wenn sie von einer „physical bottleneck to AI progress“ sprechen.
Was in der Studie oft nach Milliarden, Hyperscalern und US-Märkten klingt, ist in der Praxis deutlich greifbarer:
Die Limits sind real – sie beginnen bei der Stromverteilung im Serverraum und enden beim Liefertermin der GPUs.
Und das betrifft eben nicht nur Amazon & Co., sondern auch Forschungseinrichtungen in Baden-Württemberg oder Systemhäuser in Norddeutschland.
Gerade deshalb ist dieser McKinsey-Artikel auch lesenswert:
Er benennt klar, dass Investitionen ohne realistische Bedarfsplanung ins Leere laufen – und dass der Engpass oft nicht im Algorithmus liegt, sondern in der Infrastruktur, die ihn tragen soll.
Unser Standpunkt: Planungstiefe schlägt Hypekurven
In unserer täglichen Arbeit mit Systemhäusern, MSPs und spezialisierten OEMs erleben wir, wie schwer es ist, aus einem vagen KI-Vorhaben eine belastbare Compute-Strategie zu formen. Die McKinsey-Studie liefert wichtige Makro-Perspektiven – aber die entscheidenden Entscheidungen fallen lokal:
- Welche GPU-Server passen zu meinen Trainings- und Inferenz-Lasten?
- Wie skaliert mein Storage, wenn die Modelle wachsen?
- Welche Netzwerke und Stromversorgungen muss ich vorhalten, um Engpässe zu vermeiden?
Das sind keine Presets.
Das ist technische Planung – im Maschinenraum der Infrastruktur.
Quelle
- McKinsey & Company (Juli 2025): The cost of compute – A \$7 trillion race to scale data centers