The end customer in this project is a leading research institution focusing on demanding scientific applications such as communication technologies, X-ray technology, and adaptive systems.
Here, large amounts of data from measurements and simulations are collected, processed, and analyzed—including in image and signal processing, the optimization of complex systems, and the development of new communication methods.
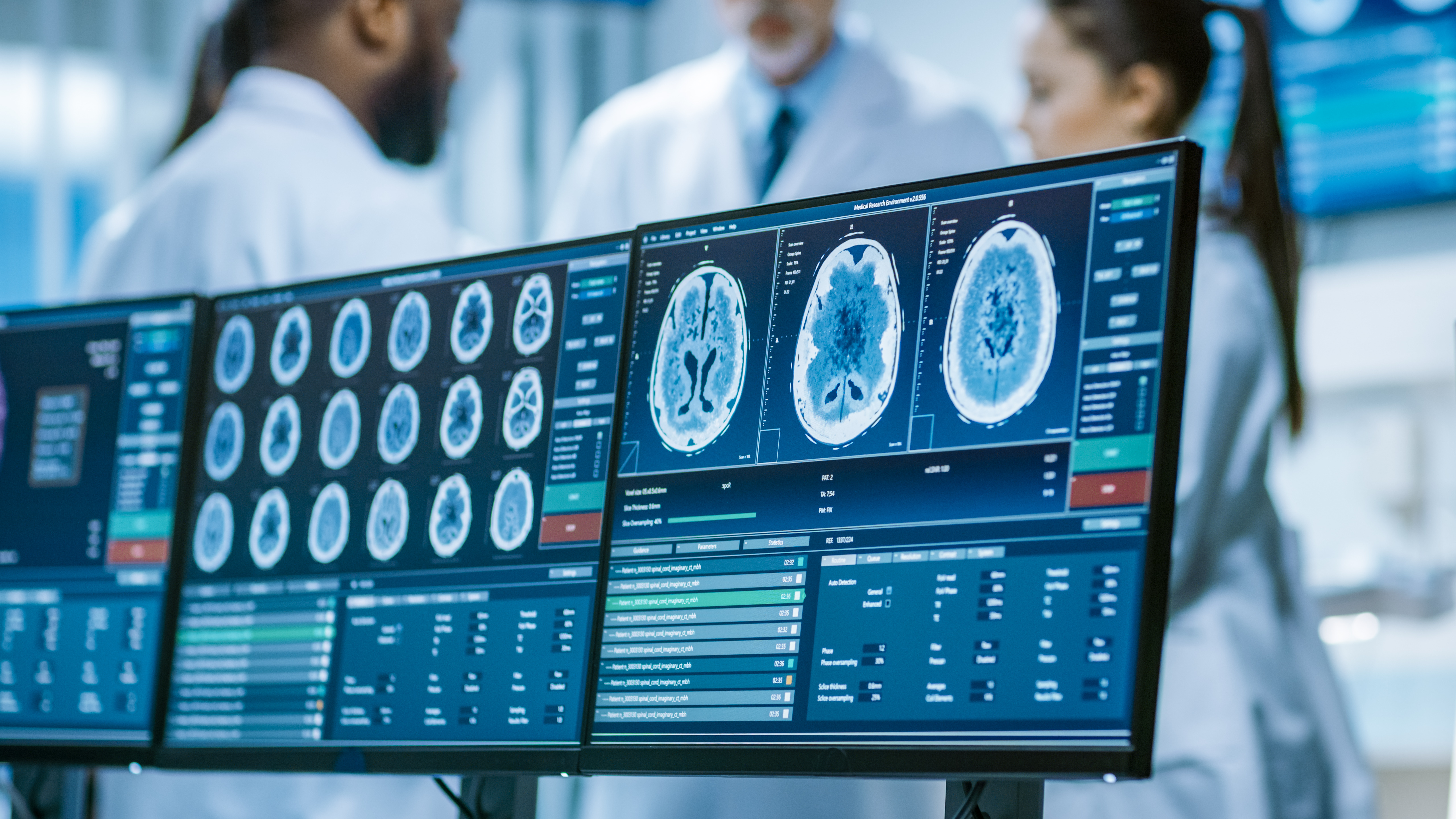
The close link between basic research and practical application ensures that results are directly incorporated into industrial solutions, for example in medical imaging or precise quality control.
To make this work efficient and expand it, the facility relies on high-performance computing (HPC) as a central tool for quickly evaluating even the largest data streams and bringing innovations to application more quickly.
Project period: Q2/2025
Project volume: High-performance GPU server solution in the six-digit euro range
Table of Contents
Project Description
The aim of the project was to expand the end customer's existing HPC environment in a targeted manner in order to meet the growing demands of modern scientific workloads.
Today, enormous amounts of data are generated in laboratories and data centers – for example, from high-resolution X-ray imaging, complex multi-channel sensor systems, or simulations of adaptive systems that have to respond to changing environmental conditions. Such data is not only storage-intensive, but also requires extremely high processing power in order to be evaluated within a reasonable time frame.
At the same time, AI-supported processes such as deep learning are becoming increasingly important. These are used at the facility for pattern recognition, system forecasting, and optimization of technical processes, among other things. These workloads benefit particularly from GPUs with enormous memory bandwidth, low latency, and an architecture that delivers maximum efficiency even in large-scale computing clusters.
The goal was to implement a GPU-optimized HPC solution that could confidently handle current peak loads while providing reserves for future projects and ensuring the stability and availability essential for 24/7 operation in a scientific data center.
Key requirements
- Maximum GPU computing power for HPC and AI workloads
- Large memory capacity with high bandwidth for parallel data processing
- Fast mass storage with low latency and high IOPS performance
- Expandability for future projects and hardware upgrades
- High availability and ESD-compliant manufacturing for reliable continuous operation
Project Implementation
Server platform
- Supermicro A+ Server AS-5126GS-TNRT
→ Rack-optimized platform with high density, redundant power supply, and powerful cooling – designed for multi-GPU operation under continuous load.
Processors
- 2× AMD EPYC 9655 (96 cores / 192 threads, 2.60 GHz, max. turbo 4.50 GHz, PCIe 5.0, 12-channel DDR5-6000)
→ Enormous parallelization capabilities and high memory bandwidth for optimal connection of GPUs and for CPU-intensive subprocesses.
Memory
- 24× 96 GB Samsung DDR5-6400 ECC reg. DR (total: 2.3 TB)
→ Large, fast, and fault-tolerant memory for memory-intensive simulations and data processing processes.
System storage
- 2× 960 GB Samsung PM893 SATA3 SSD
→ Reliable system drives with power loss protection and optimized durability in continuous operation.
Data storage
- 3× 15.36 TB Samsung PM9A3 U.2 NVMe SSD (PCIe Gen4 x4, up to 5,200 MB/s read)
→ Mass storage with high sequential performance and excellent IOPS performance – ideal for large research data sets.
GPU accelerator
- 8× NVIDIA Tesla H200 NVL PCIe (Hopper, 141 GB HBM3e per card, NVLink 900 GB/s)
→ Highest computing power and memory bandwidth for deep learning models, numerical simulations, and data-intensive analyses.
→ NVLink ensures extremely fast GPU-to-GPU communication, which significantly increases the efficiency of distributed training and simulation processes.
Additional information
- Assembly according to ISO9001:2015 / ESD IEC 61340-5-1
- 3-year parts warranty (SLA 1/3, 5x9), without pre-installed OS, tested under Linux






Result
With the new HPC server infrastructure, end customers can:
- Drastically reduce computing times – both for scientific simulations and AI training
- Process data at unprecedented speeds – thanks to optimal CPU-GPU architecture and ultra-fast NVMe storage
- Accelerate research cycles, allowing hypotheses to be tested more quickly and new approaches to be implemented faster
- Ensure future-proofing – with PCIe 5.0, expandable GPU capacity, and modular system architecture
- Work reliably in 24/7 operation – secured by ESD-compliant manufacturing, ECC memory, and redundant system components
The investment strengthens the institution's competitiveness in the international research environment and creates the technical conditions necessary to efficiently solve the most demanding scientific questions in the years to come.