
According to a recent McKinsey analysis, around $7 trillion could be invested in building computing infrastructure by 2030 – from power connections to GPU servers.
AI workloads alone are expected to require an investment of USD 5.2 trillion, spread across chips, data centers, power supply, and cooling.
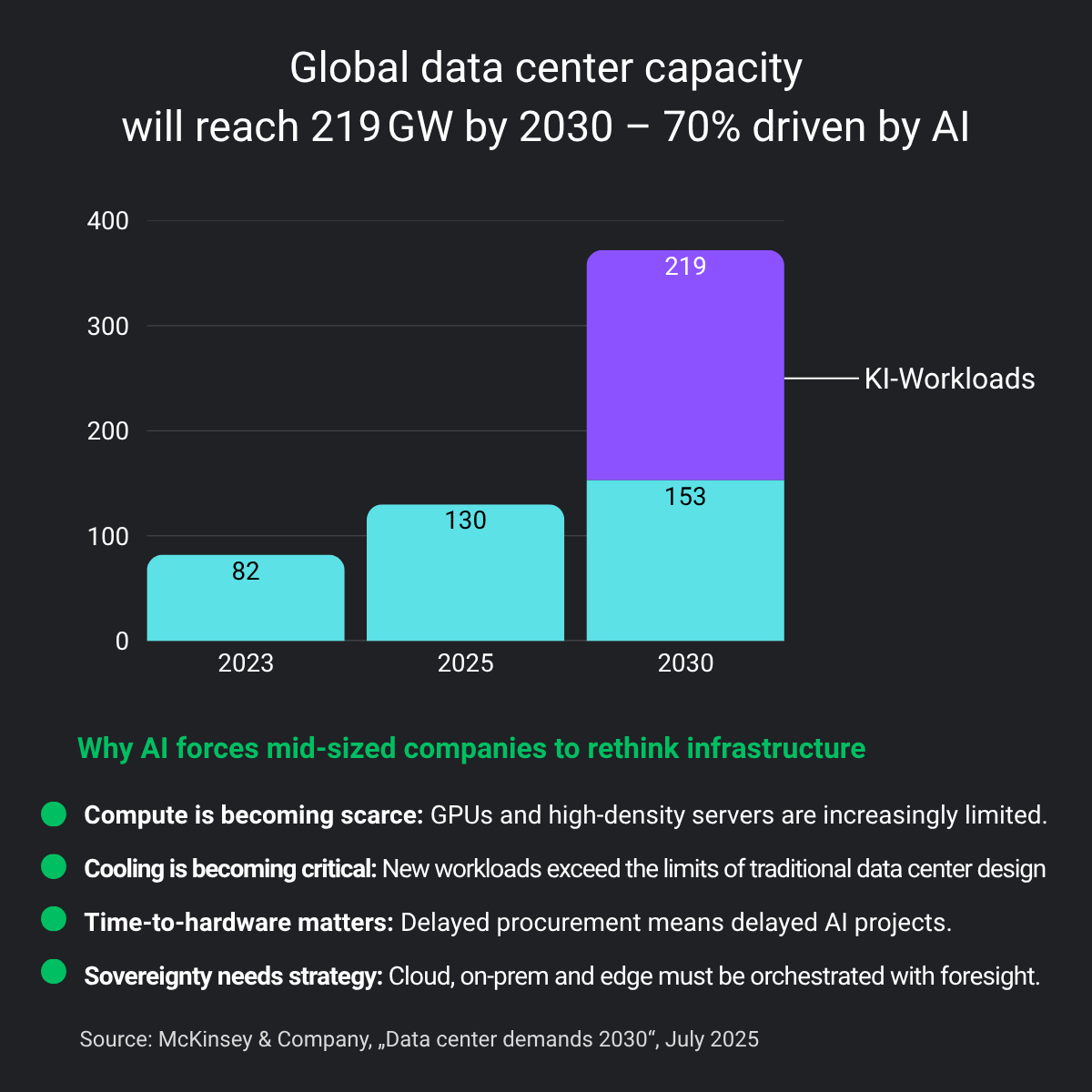
AI workloads are reshaping the cost of compute—doubling power needs and driving data center demand to unprecedented levels.
So the question is no longer whether computing power will become a bottleneck resource, but when and for whom.
There is a gap between billion-dollar forecasts and technical reality
McKinsey identifies a key challenge: the uncertainty of compute demand.
The "accelerated case" scenario assumes a 30-fold increase in AI workload by 2030. However, the range of predictions is enormous – and mistakes cost billions.
➡ The difference between underbuilding and overbuilding is becoming a key economic issue.
For us as a distributor, this is not an abstract macro forecast.
If a customer urgently needs high-end GPUs that no one in the world can deliver – or procures infrastructure months in advance that never goes live – then "demand uncertainty" becomes a real challenge in the project business.
And many system houses are all too familiar with this conflict.
At the same time, the study makes it clear that
70–80% of AI-related infrastructure costs are incurred outside the chip level.
This includes energy, space, cooling, and reliable hardware.
Compute is not arbitrarily scalable – and certainly not virtual
Even if public clouds appear to be "infinitely scalable" from the outside, the physical reality remains different:
Compute is hardware. It has to be produced, operated, cooled, and maintained.
This applies to the hyperscaler model as well as to research, industry, and small and medium-sized businesses. McKinsey rightly refers to a "physical bottleneck to AI progress" – caused by energy shortages, space constraints, infrastructure delays, and the availability of specialized components.
Those who plan too late or rely on the wrong scaling models will lose out.
What does this mean for IT decision-makers in Europe?
Many companies are already feeling the pressure – especially in regulated or performance-critical areas such as medicine, industrial automation, research, and automotive.
- Cloud-only is not enough when energy requirements, data protection, or latency become bottlenecks.
- Edge deployments are often not an "add-on" but a prerequisite for real-time capability and sovereignty.
- Hybrid strategies must be planned, not hoped for.
A concrete example:
For an international company in molecular biology drug discovery, we implemented a GPU-accelerated HPC platform in 2024 with scalable architecture, NVIDIA H100 SXM GPUs, over 900 GB/s bandwidth, and more than 512 GB RAM per system. The goal was to accelerate AI-supported processes such as virtual screening and protein structure analysis – processes in which computing time costs not only money but also research time.
The challenge was not in the software, but – as is so often the case – in the infrastructure. The focus was on:
- reliably supplying the systems with power and cooling,
- selecting the right components for simulation loads,
- and the question of how future requirements could be scaled without overbuilding.
➡ This is exactly what McKinsey means when they talk about a "physical bottleneck to AI progress."
What often sounds like billions, hyperscalers, and US markets in the study is much more tangible in practice:
The limits are real – they start with power distribution in the server room and end with the delivery date of the GPUs.
And this doesn't just affect Amazon & Co., but also research institutions in Baden-Württemberg and system houses in northern Germany.
This is precisely why this McKinsey article is worth reading:
It clearly states that investments without realistic demand planning are futile – and that the bottleneck often lies not in the algorithm, but in the infrastructure that is supposed to support it.
Our position: Planning depth beats hype curves
In our daily work with system houses, MSPs, and specialized OEMs, we experience how difficult it is to turn a vague AI project into a robust computing strategy. The McKinsey study provides important macro perspectives – but the crucial decisions are made locally:
- Which GPU servers are right for my training and inference workloads?
- How does my storage scale as the models grow?
- What networks and power supplies do I need to maintain to avoid bottlenecks?
These are not presets.
This is technical planning – in the engine room of the infrastructure.
Source
- McKinsey & Company (July 2025): The cost of compute – A \$7 trillion race to scale data centers